Making Theory Personal
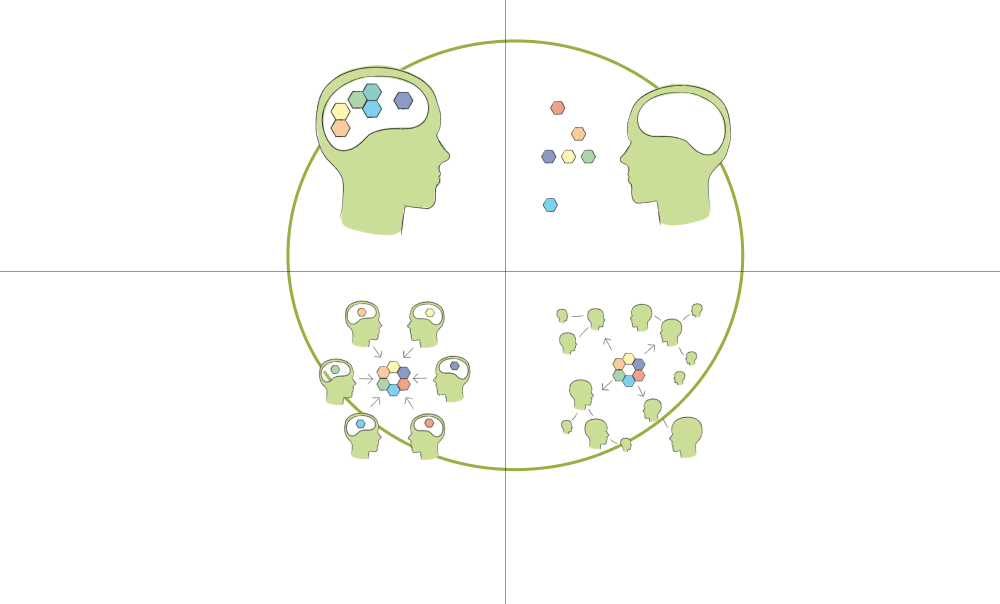
Ever stumbled upon a concept or a theory that just clicks? That sudden rush of understanding, where everything falls into place? I’ve experienced this magical moment twice in my professional life, and it’s been nothing short of transformative, not just for my career but for how I view the world. One such moment was at…
Read More